What Causes These Ideology Models to Fail?
[Version 2]*
In my last entry, I showed that newspaper reputation for political direction did not constitute as significant or substantial of an explanation of voting behavior as many political scientists had suggested over the last sixteen (16) years. Although its performance may be perfectly acceptable to some, clearly, others in the discipline seem to wish it would be strong enough to explain the bulk of what the Court does in civil liberties cases (which it does not). In this entry I take up the issue of why ideology models do not perform better.
The answer is straight forward: there are simply too many justices who do not affiliate well with the binary outcome being analyzed by the model. If a logit model was a drain, centrists justices are the clog. And that means that “newspaper ideology models” are really nothing other than a partially-clogged piece of plumbing. To demonstrate this, examine the stepwise analysis (Table 5 in my SSRN paper). It begins with the logit results of Segal and Spaeth’s base ideology model, updated to 2004. It then subtracts the justice with a liberal rating closest to pure non-direction (.5) and re-estimates the regression. The subtraction continues one justice at a time until only those justices with ratings above 66.1 (Ginsburg) and below 33.9 remain. The subtraction increment is 16.1 points above or below 50%. As each median justice is subtracted, the values of the regression increase remarkably. At the very end of the regression, Justice Douglas is added. By this time, the only justices remaining in the analysis are the following ten: Brennan, Burger, Fortas, Goldberg, Marshall, Rehnquist, Scalia, Thomas, Warren and Douglas.
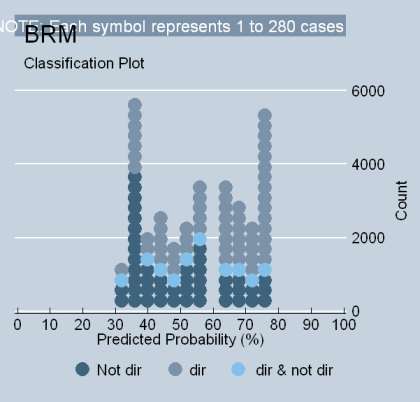
The table is simply amazing. The model has been transformed from “clogged plumbing” to Niagara Falls. It now has a KDV of 78 points and increases the ability classify the direction of votes by 57%. The total voting variance explained by the model is also 57% (phi-p). Or, stated another way, “Rehnquist votes the way he does because he is conservative; Marshall voted the way he did because he is liberal.” To really see the effect of “clan voting,” examine the classification plot below. It shows quite clearly why the model performs so well: there are no justices clustered around the 50% mark, and the model has two solid anchors on each side:
What does this show? It demonstrates is that one cannot create a bivariate ideology model that has the level of explanation that Segal and Spaeth originally believed they had created – a model that explains at least 60% of the Court’s choices – without first removing every justice from the truncated model having a liberal rating within 34% and 66.2% (and adding Douglas).[i] What this also says is that scholars who are championing the idea of an ideologically-driven Court are simply allowing the votes of those justices with the most obstinate judicial personalities to stereotype the majority of the institutional-membership’s voting behavior.
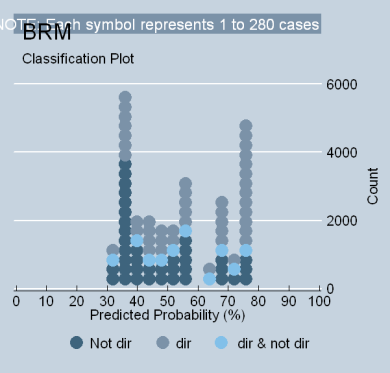
To see this, consider the model in Table 6 of my SSRN paper. It analyzes civil liberties voting from 1946-2004, but excludes 8 of the most directional justices having liberal ratings below 23% and over 77% (Rehnquist, Goldberg, Fortas, Douglas, Marshall, Brennan, Murphy and Warren). One of the reasons why excluding outliers is relevant, of course, is that the current Court no longer contains membership with career propensities beyond the values being excluded. Hence, one could argue that this analysis is a better estimation of the degree to which justice ideology governs votes on the current Court, [ii] at least to the extent researchers claim to have observed such phenomena in the Supreme Court data base.
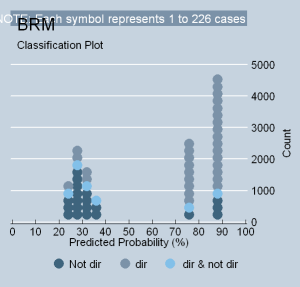
The result of the subtraction is simply remarkable. The index variance explained by the regression drops to 17%. Total voting variance drops to 9% (phi-p), and PRE is only 11% (tau-p). The coefficient in the logit regression indicates that liberal ratings only increase by 8 discreet points as Segal/Cover scores change by 100% (KDV). The classplot in Table 3, Figure 6, speaks for itself. But what is perhaps more interesting is what happens if the subtraction range is increased by one percentage point in each direction (24% to 76%). It results in the exclusion of only two additional justices (Thomas and Rutledge) and produces a statistically-insignificant ecological model. [iii] It is indeed remarkable that an ecological model is completely unable to explain the liberal ratings of nearly two-thirds (22) of the Court’s membership since 1946, and that, whatever level of explanation it otherwise achieves is simply driven by a small minority of the Court’s most obstinate personalities.
[i] Some may be tempted to object that this manuscript sets up a test of the attitudinal model that requires justices to vote perfectly liberal or conservative before “attitudinalism” can prevail. This is not accurate. The manuscript merely requires that the career choices of the largely non-directional justices be similar to the directional before the bivariate model can be regarded as systemically dominant as proponents of ecological regression claimed. Indeed, what this manuscript demonstrates is only that what researchers empirically operationalized as “attitudinalism” simply plays a smaller role than previously thought. Finally, it should be remembered that there are three pathways to higher numbers in these models: (a) extreme justices voting with less dependency (see Figure 2 in Table 3); (b) middle justices voting like affiliated ones; or (c) some combination of the two.
[ii] Although the career propensities of Justices Alito and Roberts are not yet known, it is perhaps worth mentioning that both justices are predicted to be in the “moderately conservative” range. Alito’s newspaper reputation for political values was -0.8. His career liberalism is estimated to be 0.355 using a logit model and 0.343 using an ecological model. Justice Roberts’ newspaper reputation, by contrast, was -0.76, making his estimated liberalism 0.364 (logit) and .351 (ecological). However, it must be remembered that these forecasts are not remarkably accurate. The absolute value of the average mistake is 13 points for ecological regression and 13.1 for logit regression. Therefore, one cannot say that Alito or Roberts will not be especially directional. This caveat must be kept in mind when considering whether a regression that excludes outliers is a more accurate model of today’s Court.
[iii] There are other voting circumstances where Segal/Cover scores produce statistically insignificant results in civil liberties cases. Newspaper reputation is a statistically insignificant predictor (p values greater than .1) for every civil liberties vote cast by justices in the years of 1950, 1954, 1964, and 1992 (95% confidence interval, two tailed test). The p-values are also greater than .01 for the years 1949, 1951, 1952, 1953, 1965, 1968, 1991 and 1993 (Wilson 2006).
* substantial edit
 Sean Wilson
Sean Wilson